


Apache Tez is an extensible framework for building high performance batch and interactive data processing applications, coordinated by YARN in Apache Hadoop. Tez improves the MapReduce paradigm by dramatically improving its speed, while maintaining MapReduce’s ability to scale to petabytes of data.
YARN considers all the available computing resources on each machine in the cluster. Based on the available resources, YARN negotiates resource requests from applications running in the cluster, such as MapReduce. YARN then provides processing capacity to each application by allocating containers. A container is the basic unit of processing capacity in YARN, and is an encapsulation of resource elements (for example, memory, CPU, and so on).
In a Hadoop cluster, it is important to balance the memory (RAM) usage, processors (CPU cores), and disks so that processing is not constrained by any one of these cluster resources. Generally, allow for 2 containers per disk and per core for the best balance of cluster utilization.
This article is meant to outline the best practices on memory management of application master and container, java heap size and memory allocation of distributed cache.
Environment – Apache Hive 1.2.1 and Apache Tez 0.7.0
Keywords – Hadoop, Apache Hive, Apache Tez, HDFS, YARN, Map Reduce, Application Master, Resource Manager, Node Manager, Cluster, Container, Java Heap, Apache HBase, YARN Scheduler, Distributed Cache, Map Join, Stack Memory, RAM, Disk, Output Sort Buffer
Few configuration parameters which are important in context of jobs running in the Container are described below -
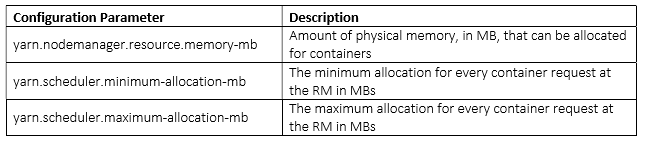

Calculating YARN and MapReduce Memory Configuration
When determining the appropriate YARN and MapReduce memory configurations for a cluster node, start with the available hardware resources. Specifically, note the following values on each node:
- RAM (Amount of memory)
- CORES (Number of CPU cores)
- DISKS (Number of disks)
The total available RAM for YARN and MapReduce should consider the Reserved Memory. Reserved Memory is the RAM needed by system processes and other Hadoop processes (such as HBase).
Reserved Memory = Reserved for stack memory + Reserved for HBase Memory (If HBase is on the same node).
Use the following table to determine the Reserved Memory per node.
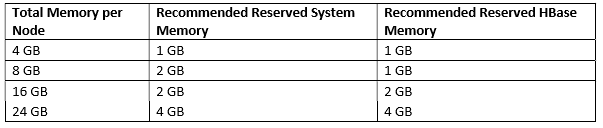

The total YARN memory on all nodes usually between 75% and 87.5% of RAM.
There are two methods used to determine YARN and MapReduce memory configuration settings
- Running the YARN Utility Script
- Manually Calculating YARN and MapReduce Memory Configuration Settings
The HDP utility script is the recommended method for calculating HDP memory configuration settings, but information about manually calculating YARN and MapReduce memory configuration settings is also provided for reference.
Running YARN Utility scriptHDP provides a utility script called hdp-configuration-utils.py script to calculate YARN, MapReduce, Hive, and Tez memory allocation settings based on the node hardware specifications.
To run the hdp-configuration-utils.py script, execute the following command from the folder containing the script hdp-configuration-utils.py options where options are as follows:

Running the following command:
|
python hdp-configuration-utils.py -c 16 -m 64 -d 4 -k True |
The output would look like below -


In Ambari, configure the appropriate settings for YARN and MapReduce or in a non-Ambari managed cluster, manually add the first three settings in yarn-site.xml and the rest in mapred-site.xml on all nodes.
Manually Calculating YARN and MapReduce Memory Configuration
In yarn-site.xml, set yarn.nodemanager.resource.memory-mb to the memory that YARN uses:
- For systems with 16GB of RAM or less, allocate one-quarter of the total memory for system use and the rest can be used by YARN.
- For systems with more than 16GB of RAM, allocate one-eighth of the total memory for system use and the rest can be used by YARN.
yarn.scheduler.maximum-allocation-mb is the same as yarn.nodemanager.resource.memory-mb.
yarn.nodemanager.resource.memory-mb is the total memory of RAM allocated for all the nodes of the cluster for YARN. Based on the number of containers, the minimum YARN memory allocation for a container is yarn.scheduler.minimum-allocation-mb. yarn.scheduler.minimum-allocation-mb will be a very important setting for Tez Application Master and Container sizes. The total YARN memory on all nodes usually between 75% and 87.5% of RAM as per the above calculation.
Calculation to determine the max number of containers per node
Configuration parameter i.e. tez.am.resource.memory.mb and hive.tez.container.size define Tez application master size and container size respectively.
Set tez.am.resource.memory.mb to be the same as yarn.scheduler.minimum-allocation-mb (the YARN minimum container size)
Set hive.tez.container.size to be the same as or a small multiple (1 or 2 times that) of YARN container size yarn.scheduler.minimum-allocation-mb but NEVER more than yarn.scheduler.maximum-allocation-mb. You want to have headroom for multiple containers to be spun up.
The formula for determining the max number of container allowed per node is
# of containers = min (2*CORES, 1.8*DISKS, (Total available RAM) / MIN_CONTAINER_SIZE)
Here DISKS is the value for dfs.data.dirs (number of data disks) per machine and MIN_CONTAINER_SIZE is the minimum container size (in RAM). This value is dependent on the amount of RAM available. In smaller memory nodes, the minimum container size should also be smaller. The following table outlines the recommended values.

Calculation to determine the amount of RAM per container
The formula for calculating the amount of RAM per container is
RAM per container = max(MIN_CONTAINER_SIZE, (Total Available RAM) / containers))
With these calculations, the YARN and MapReduce configurations can be set.

Note: please refer output section of #running YARN utility script, to get the exact value of these configuration parameter for a cluster having cores=16, memory=64GB and disks=4.
Calculation to determine Java heap memory of Application Master and Container
Configuration parameter tez.am.launch.cmd-opts and hive.tez.java.ops define java hea memory of Application master and Container respectively.
The heap memory size would be 80% of the container sizes, tez.am.resource.memory.mb and hive.tez.container.size respectfully.

Calculation to determine Hive Memory Map Join Settings parameters
A map-side join is a special type of join where a smaller table is loaded in memory (distributed cache) and join is performed in map phase of MapReduce job. Since there is no reducer involved in the map-side join, it is much faster when compared to regular join.
hive.auto.convert.join.noconditionaltask.size is the configuration parameter to size memory to perform Map Joins.
By default hive.auto.convert.join.noconditionaltask = true
Formula to set the size of the map join is 33% of container size.
i.e.
SET hive.auto.convert.join.noconditionaltask.size to 1/3 of hive.tez.container.size
Calculation to determine the size of the sort buffer
tez.runtime.io.sort.mb is the configuration parameter which defines the size of the soft buffer when output is sorted.
Formula to calculate the soft buffer size is 40% of the container size.
SET tez.runtime.io.sort.mb to be 40% of hive.tez.container.size.
tez.runtime.unordered.output.buffer.size-mb is the memory when the output does not need to be sorted. Its value is 10% of container size
SET tez.runtime.unordered.output.buffer.size-mb to 10% of hive.tez.container.size
A quick summary
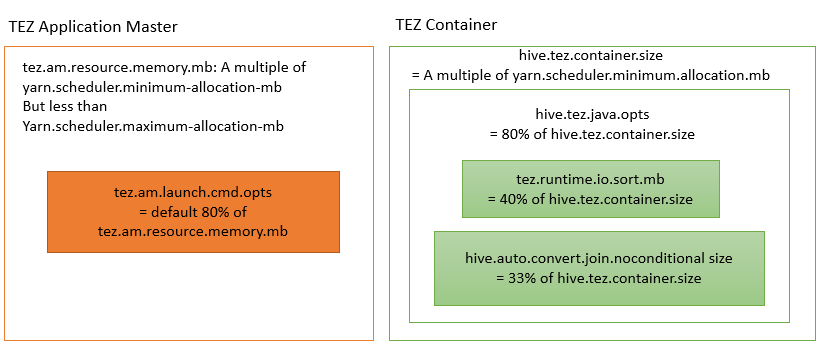
(Fig to understand the properties with their calculated values)
Example
Considering a Cluster nodes having 16 CPU cores, 64 GB RAM, and 4 disks.
Reserved Memory = 8 GB reserved for system memory + 8 GB for HBase = 16 GB
If there is no HBase:
# of containers = min (2*16, 1.8* 16, (64-8)/2) = min (32, 28.8, 28) = 28
RAM per container = max (2, (64-8)/28) = max (2, 2) = 2

If HBase is included:
# of containers = min (2*16, 1.8* 16, (64-8-8)/2) = min (32, 28.8, 24) = 24
RAM-per-container = max (2, (64-8-8)/24) = max (2, 2) = 2

Note – As container size is multiply of yarn.scheduler.minimum-allocation-mb, 2 multiple of yarn.scheduler.minimum-allocation-mb (i.e. 2048 * 2 = 4096 MB is the recommended configuration)
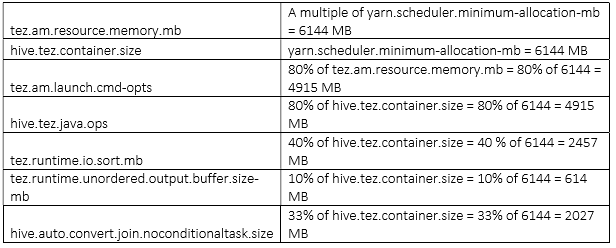
Conclusion
The minimum allocation for every container request at the RM is 1024 MB. Memory requests lower than this won't take effect, and the specified value will get allocated at minimum. The maximum allocation for every container request at the RM is 8192 MB. Memory requests higher than this won't take effect, and will get capped to this value.
The RM can only allocate memory to containers in increments of yarn.scheduler.minimum-allocation-mb and not exceed yarn.scheduler.maximum-allocation-mb
If one job is asking for 1030 MB memory per map container (set mapreduce.map.memory.mb=1030), RM will give it one 2048 MB (2*yarn.scheduler.minimum-allocation-mb) container because each job will get the memory it asks for rounded up to the next slot size. If the minimum is 4GB and the application asks for 5 GB, it will get 8GB. If we want less rounding, we must make the minimum allocation size smaller.
The HEAP memory configuration is 80% of container size and its not 100% because the JVM has some off heap overhead that still counts into the memory consumption of the Linux process.
References
https://cwiki.apache.org/confluence/display/Hive/Hive+on+Tez
https://cwiki.apache.org/confluence/display/Hive/Configuration+Properties
.svg)

.svg)